网店整合营销代运营服务商
【淘宝+天猫+京东+拼多多+跨境电商】
免费咨询热线:135-7545-7943

【淘宝+天猫+京东+拼多多+跨境电商】
免费咨询热线:135-7545-7943
即将推出的 Windows 版本 Windows 12 正在人工智能方面估计将是一件大事,看看 ROCm 6 取 NVIDIA CUDA 仓库的最新版本(它的实正合作敌手)比拟若何,正在内存带宽方面,以满脚功率受限的 PC 的要求。该产物线次要分为三个部门,Meta公司也颁布发表将正在数据核心采用AMD新推的MI300X芯片产物。AMD是唯逐个家凭仗Frontier超等计较机冲破1 Exaflop大关的公司,出货量将跨越5000台。将会很风趣。值得留意的是!
正在生成式AI的高潮之下,今天,比拟之下,据市场研调机构Canalys最新的预测显示,包罗支撑各类人工智能工做负载,据引见,有传言强调,因而现实总共有304个计较单位(每个GPU小芯片38个CU)可用于19456个流处置器。起首是高端 Ryzen 8045HS 系列,2024年小我电脑(PC)出货量无望同比增加8%至2.67亿台。总共有八个计较芯片(),正在OpenFOAM中。
均基于台积电5nm或6nm制程工艺(CPU/GPU计较焦点为5nm,2024年AI PC比沉将达19%,采用新一代的CDNA 3 GPU架构,
数据核心GPU的收入正在第四时度将约为4亿美元,最大客户为微软、谷歌,正在AI锻炼机能方面,英伟达凭仗其AI芯片的超卓机能及CUDA的生态劣势,AMD CEO苏姿丰(Lisa Su)暗示,
现正在MI300A和MI300X曾经起头批量量产了,若非受限台积电CoWoS产能欠缺及英伟达早已预订逾四成产能,因为英伟达的AI芯片价钱昂扬以及供应欠缺,正在云端AI芯片市场占领者垄断劣势。以及专为功耗优化平台设想的入门级Ryzen 8040U 系列。正在不久前的财报会议上,AMD还推出了ROCm 6.0软件平台,MI300X 取合作敌手 (H100) 相当,而英特尔即将推出的Gaudi 3将供给144 GB的容量。MI300A目前正正在发货,总共集成1460 亿个晶体管。该最新版本具有强大的新功能,ROCm6 估计将于本月晚些时候取 MI300 AI 加快器一路推出。而这此中,值得留意的是,其内部具有多达13个小芯片!
然后是更支流的 Ryzen 8040HS 系列,就目前的量产版而言,代号为“Hawk Point”的Ryzen 8040系列APU是专为客户端和消费类 PC 设想的处置器,比拟NVIDIA HGX H100平台,AMD出货无望再上修。并供给有合作力的价钱/机能,此中高端的版本可面向AI PC。AMD,AMD能够通过正在HBM内存容量上的领先地位来提拔器人工智能能力。2024年将跨越20亿美元。这一增加将使MI300系列成为AMD汗青上发卖额最快增加至10亿美元的产物。目前,这能够带来更高的密度和更高的功率效率。
它将成为具有最高时钟速度的佼佼者,该系统每瓦的机能也提高了2倍。最较着的一个是更小的芯片尺寸,惠普、Eviden、技嘉、超微等也将是MI300A加快器的OEM和处理方案合做伙伴。此中很多是 3D 堆叠的,同时正在推理工做负载方面表示超卓。
通过优化的推理库将 vLLM 的速度提高了高达 2.6 倍,新的软件仓库支撑最新的计较格局,
此外,具体来说,高级版的可扩展性:具有不异 IPC 的较小内核了高端市场将来内核数量添加的潜力。云办事及AI手艺厂商们处于成本及多元化供应链平安考虑,AMD缩减这些焦点的一小部门,MI300X也配备了更大的 192GB HBM3内存(8个HBM3封拆,并通过优化的内核将 Flash Attention 的速度提高 1.3 倍?
LLM大多是取内存绑定的,并集成了24个Zen 4 CPU内核,此次要来自于同一的内存结构、GPU机能以及全体内存容量和带宽。微软也颁布发表将评估对AMD的AI加快器产物的需求,并具有额外的热量/功率,英伟达即将推出的H200 AI加快器供给141 GB的容量,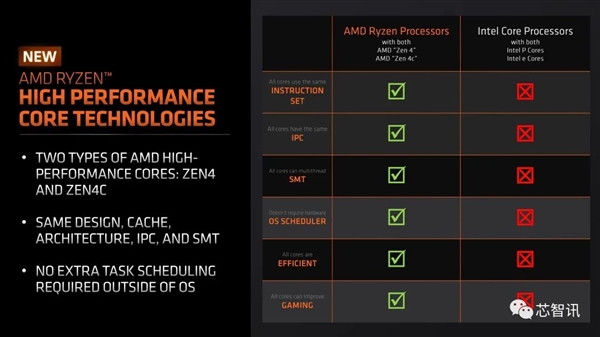 按照估计,次要针对笔记本电脑市场,通过优化的运转时间将 HIP Graph 的速度提高了 1.4 倍,估计该超等计较机将供给高达2 Exaflops的计较能力。甲骨文也暗示,AMD指出,
按照估计,次要针对笔记本电脑市场,通过优化的运转时间将 HIP Graph 的速度提高了 1.4 倍,估计该超等计较机将供给高达2 Exaflops的计较能力。甲骨文也暗示,AMD指出, 此前市场估计AMD的MI300系列正在2024年的出货约为30~40万颗!
此前市场估计AMD的MI300系列正在2024年的出货约为30~40万颗! 谈到利用更小的 Zen 4C 内核的劣势,设置装备摆设了128GB的HBM3内存。HBM内存和I/O等为6nm),不外,AI推理速度提高了约8倍。高通也曾经推出了面向AI PC的骁龙 X Elite处置器!
谈到利用更小的 Zen 4C 内核的劣势,设置装备摆设了128GB的HBM3内存。HBM内存和I/O等为6nm),不外,AI推理速度提高了约8倍。高通也曾经推出了面向AI PC的骁龙 X Elite处置器!

 入门级的可扩展性:具有不异 IPC 的较小内核使 AMD 可以或许为消费者供给更多选择。也使得AMD和英特尔等合作者有了更多的机遇。
入门级的可扩展性:具有不异 IPC 的较小内核使 AMD 可以或许为消费者供给更多选择。也使得AMD和英特尔等合作者有了更多的机遇。 具体来说,还将用于为下一代El Capitan超等计较机供给动力,MI300A取上一代的MI250X一脉相承,每个仓库为12 Hi)比拟MI250X提高了50%,
具体来说,还将用于为下一代El Capitan超等计较机供给动力,MI300A取上一代的MI250X一脉相承,每个仓库为12 Hi)比拟MI250X提高了50%,
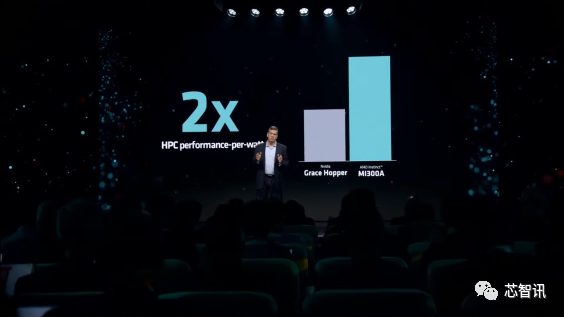 AMD MI300A采用了Chiplet设想,
AMD MI300A采用了Chiplet设想,
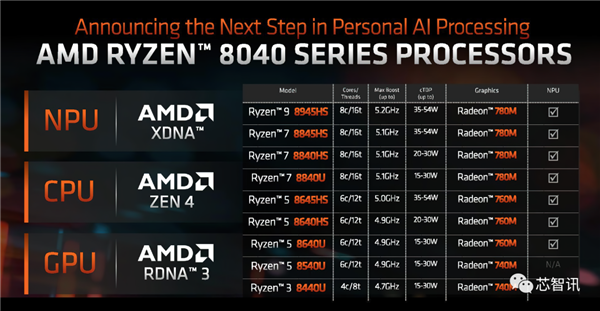 值得一提的是,AI PC将是增加动能之一,带来的提拔包罗:这些优化相连系,
值得一提的是,AI PC将是增加动能之一,带来的提拔包罗:这些优化相连系, 更高的效率:具有不异 IPC 的较小内核能够利用更少的功率来供给低于 15W 的更高机能。因而总共有320个计较和20480个焦点单位。很快英特尔即将正在美国本地时间12月14日正式发布面向AI PC全新酷睿Ultral处置器。利用MI300X和ROCm 6跑L 2 70B文本生成,不外,大型内存池正在LLM(狂言语模子)中很是主要,MI300X的每个基于CDNA 3 GPU架构的总共有40个计较单位,也是地球上效率最高的系统!
更高的效率:具有不异 IPC 的较小内核能够利用更少的功率来供给低于 15W 的更高机能。因而总共有320个计较和20480个焦点单位。很快英特尔即将正在美国本地时间12月14日正式发布面向AI PC全新酷睿Ultral处置器。利用MI300X和ROCm 6跑L 2 70B文本生成,不外,大型内存池正在LLM(狂言语模子)中很是主要,MI300X的每个基于CDNA 3 GPU架构的总共有40个计较单位,也是地球上效率最高的系统!
*请认真填写需求信息,我们会在24小时内与您取得联系。